 Training Deep Structured Prediction Models at Scale
Training Deep Structured Prediction Models at Scale
Dec 17, 2018
This post discusses the use of smoothing and accelerated incremental algorithms for faster training of structured prediction models
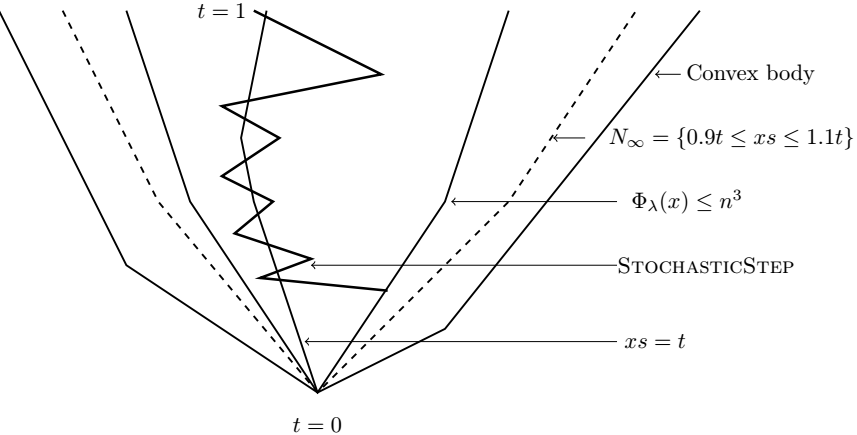 Stochastic Central Path & Projection Maintenance
Stochastic Central Path & Projection Maintenance
Oct 20, 2018
Solving Linear Programs in the Current Matrix Multiplication Time
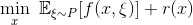 Stochastic subgradient method converges at the rate \(O(k^{-1/4})\) on weakly convex functions
Stochastic subgradient method converges at the rate \(O(k^{-1/4})\) on weakly convex functions
Apr 2, 2018
Recent breakthrough on using proximal stochastic gradient method for weakly convex functions.
 Acoustic models for music transcription
Acoustic models for music transcription
Mar 15, 2018
Recent work on music-to-score alignment and translation-invariant networks for music transcription
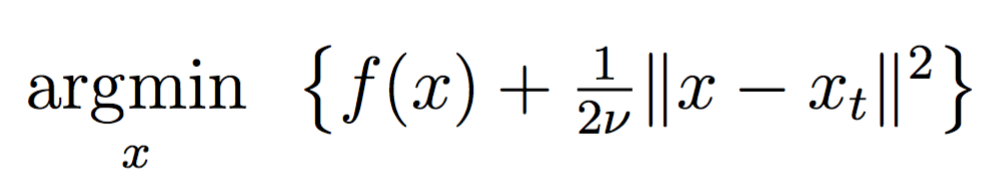 Proximal point algorithm revisited, episode 3. Catalyst acceleration
Proximal point algorithm revisited, episode 3. Catalyst acceleration
Feb 6, 2018
Revisiting the proximal point method, and catalyst generic acceleration for regularized Empirical Risk Minimization.
Proximal point algorithm revisited, episode 2. The prox-linear algorithm
Jan 31, 2018
Revisiting the proximal point method. Composite models and the prox-linear algorithm.
Proximal point algorithm revisited, episode 1. The proximally guided subgradient method
Jan 25, 2018
Revisiting the proximal point method, with the proximally guided subgradient method for stochastic optimization.
The proximal point method revisited, episode 0. Introduction
Jan 25, 2018
Revisiting the proximal point method. Introduction and Notation.
 k-server problem
k-server problem
Jan 11, 2018
Recent breakthrough of the k-server problem on HST


